topology spread constraints and blue/green deployments
by on Saturday, 25 February 2023
This week I discovered a flaw in our topology spread constraints.
It’s weird enough (or at least interesting enough) that I think it’s worth sharing.
This is kubernetes by the way.
And I'm talking about the topologySpreadConstraints field.
(Did you know that k8s is just counting the 8 missing letters between the k and the s.)
(I didn’t until I’d been using k8s in production for 2 years already.)
the setup
The app in question is powered by a statefulset.
Each pod has a persistent volume attached.
(Hence the statefulset.)
In our staging environment, we only run 2 pods.
Request volume is minimal and there’s no need to burn cash.
the problem
Since the day before, around 19:00, one of the two pods was always in state Pending.
It couldn’t be created due to a bunch of taint violations and other stuff.
Normal NotTriggerScaleUp 4m38s (x590 over 109m) cluster-autoscaler (combined from similar events): pod didn't trigger scale-up: 1 in backoff after failed scale-up, 6 node(s) had taint {workload: always-on}, that the pod didn't tolerate, 3 node(s) had taint {workload: mog-gpu}, that the pod didn't tolerate, 3 node(s) had taint {workload: mog}, that the pod didn't tolerate, 3 node(s) had taint {workload: default-arm}, that the pod didn't tolerate, 3 node(s) had taint {workload: nvidia-gpu}, that the pod didn't tolerate, 4 node(s) had volume node affinity conflict, 1 node(s) didn't match pod topology spread constraints, 3 node(s) had taint {workload: prometheus}, that the pod didn't tolerate
(That "code block" is big, you might have to scroll for a while to see the end.)
I don’t fully understand what all the other stuff is, I’m a kubernetes user, not an administrator.
The staging cluster runs on spot instances.
Permanently having one pod Pending, we sometimes had the other pod evicted.
This left us with zero pods.
Zero pods is bad for availability.
Our on-call engineer got woken up at 04:00.
They then got woken up again at 09:00.
Because they’d already been woken up at 04:00, so they were trying to sleep in.
Being woken up in the middle of the night for the staging environment is actually the bigger problem here.
But it’s not the interesting problem.
The interesting problem is why only one of two pods could be started.
the investigation
Here we get into the good stuff.
I asked our platform team why one of our pods was always in pending state.
They discovered that it was because the 2 persistent volumes were in the same availability zone.
This is in violation of the topology spread constraints that we had specified.
That's this part of the NotTriggerScaleUp message:
1 node(s) didn't match pod topology spread constraints
aside: topology spread constraints
Topology spread constraints are the current best way to control where your pods are allocated.
Stable in kubernetes 1.24.
(I think, please tell me if this is wrong, couldn't find better information.)
This is better than pod affinity and anti-affinity rules which were already available.
A topology spread constraint allows you to say things like:
"I want my pods to be spread across all availability zones equally."
That phrase isn't precise enough, we need to work on it.
"I want my pods to be spread across all availability zones equally."
To properly define my pods we use labels.
So, my pods would actually be, all the pods with the label app=my_app.
Or you can use multiple labels.
Equally is not always possible.
Instead, I'll ask for a maximum skew=1.
The skew is the difference between the availability zone with least pods and the one with most.
If I have 5 pods I they could be allocated as A: 1, B: 2, C: 2.
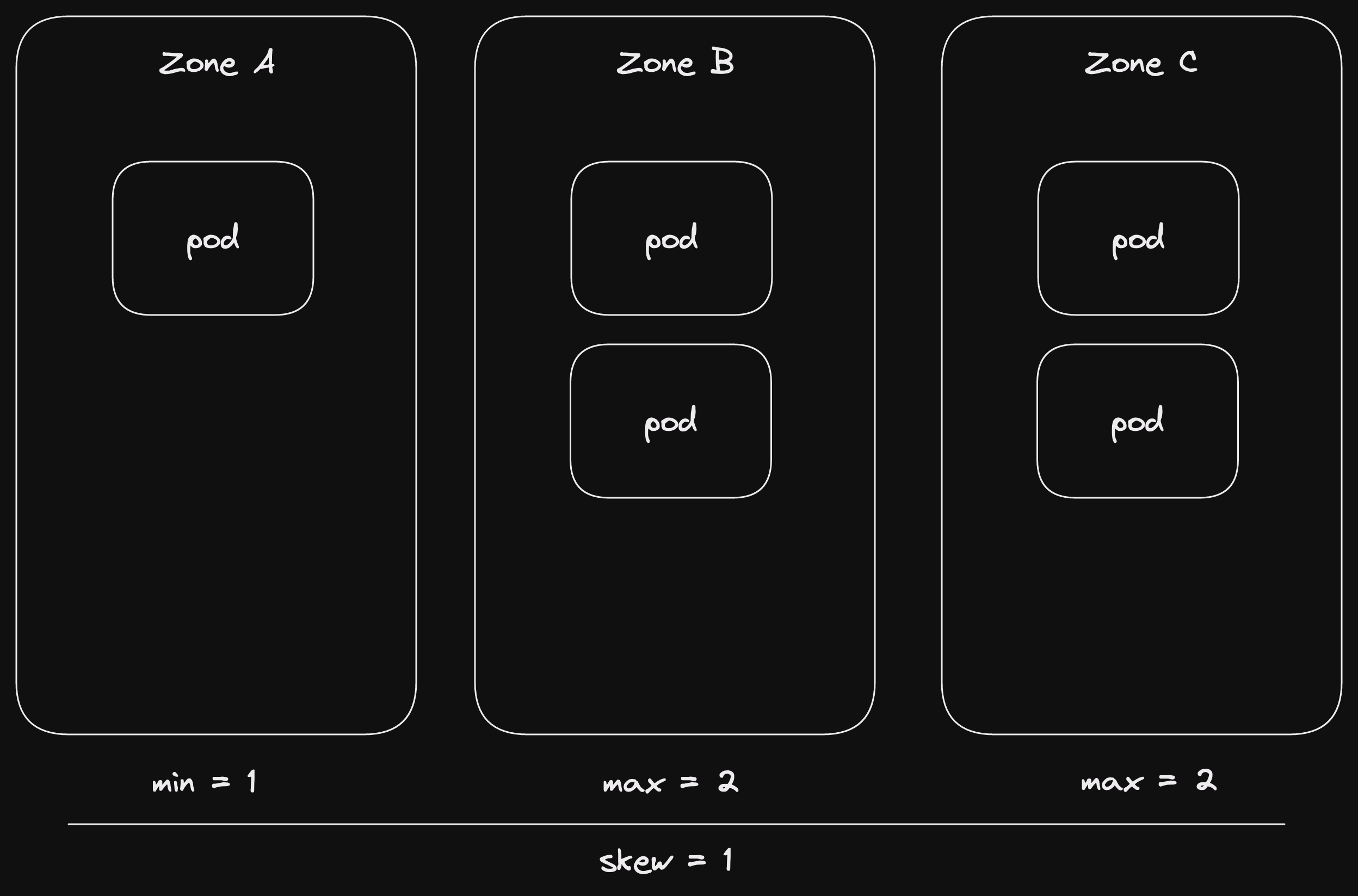
Maximum number of pods per zone is 2, minimum is 1.
skew=1 (which is less than or equal to 2 - 1 = 1).
They can't be allocated as A: 1, B: 1, C: 3.
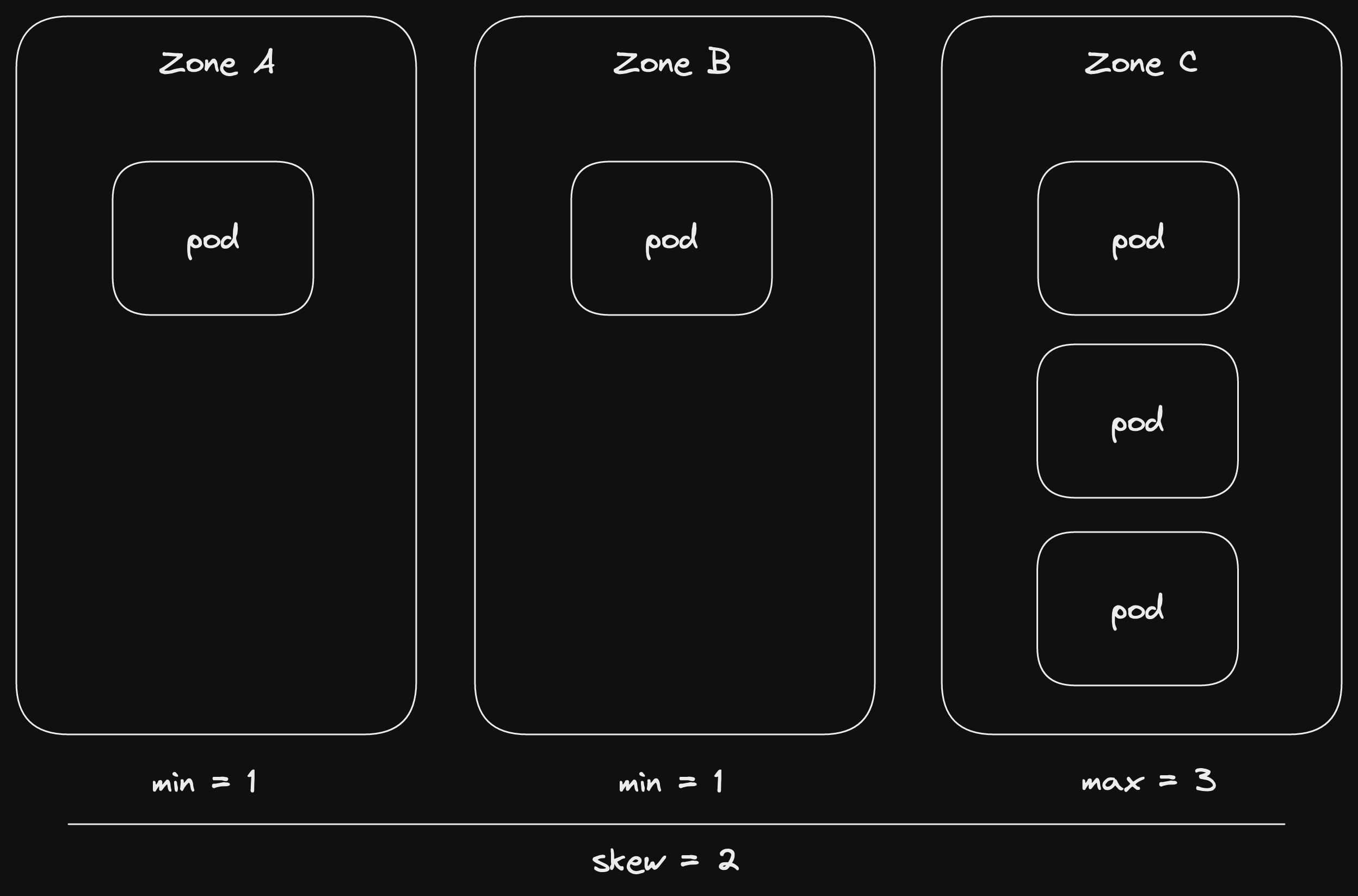
Then the skew is is 3 - 1 = 2.
And 2 is greater than our desired skew=1.
As well as availability zone, we could use hostname (which means node).
back to the investigation
Now we know about topology spread constraints, we can continue.
The persistent volume for each pod is created new for each deployment.
So how could both persistent volumes be in the same availability zone.
Our topology spread constraint would not have allowed it!
Then another member of the platform team asked:
"With blue/green deployments, I see a topology spread constraint that would be shared between multiple statefulsets?"
"Hm, or maybe not. Those are probably restricted to the single statefulset."
Then came the forehead slapping moment.
And I went searching in our Helm chart to confirm what I already new.
Our topology spread constraints are like the example above.
They apply to all pods with the label app=my_app.
This makes sense, as in the same namespace we have separate deployments/statefulsets.
So we have topology spread constraints for app=my_app, app=other_app, etc.
But we do blue/green deployments!
aside: blue/green deployments
Blue/green is a zero-downtime deployment technique.
You start with a single current deployment.
This is your blue deployment, all the user requests go there.
Because it's the only deployment.
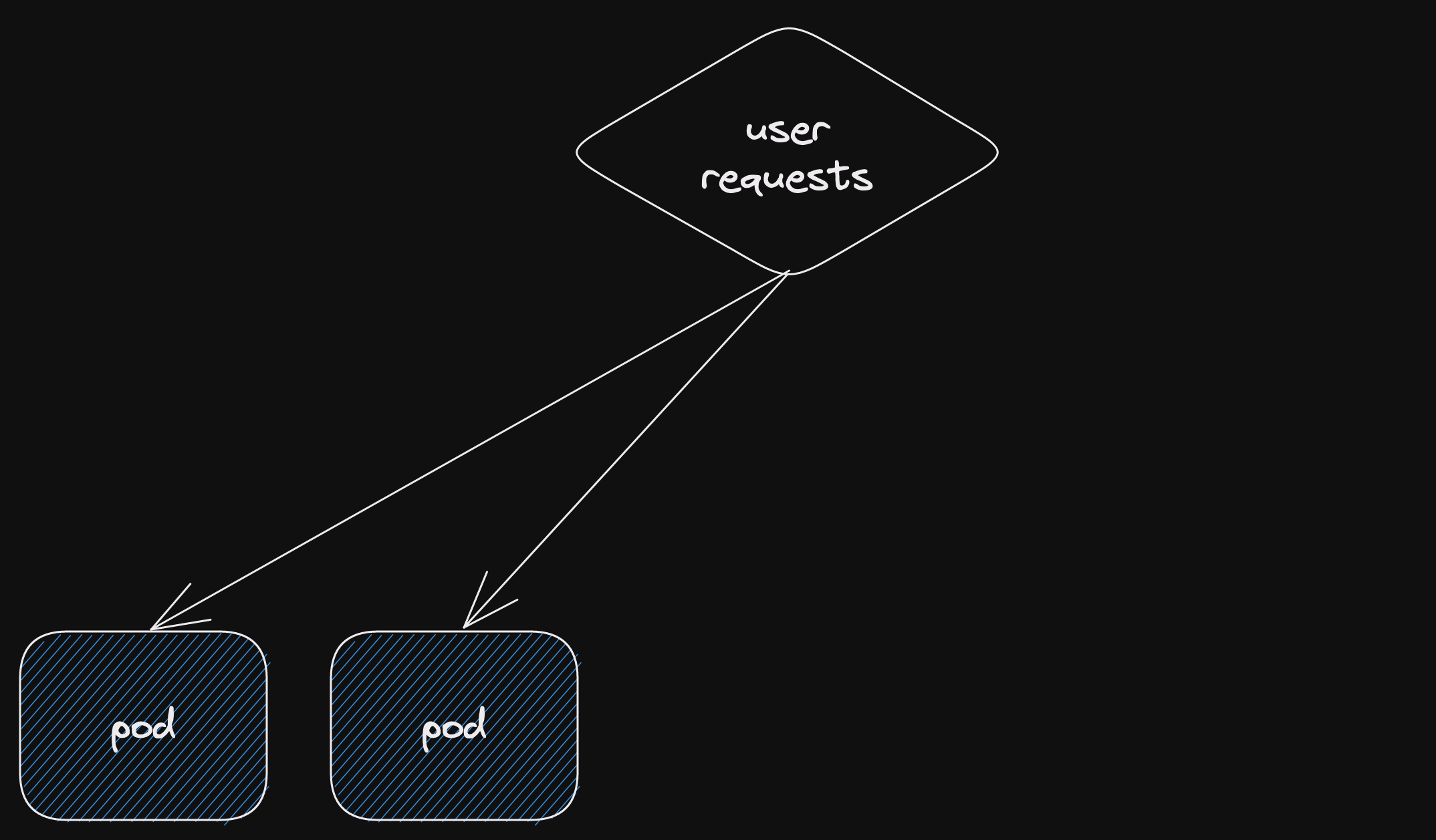
Now you add another deployment.
This is your green deployment, it isn't receiving any user requests yet.
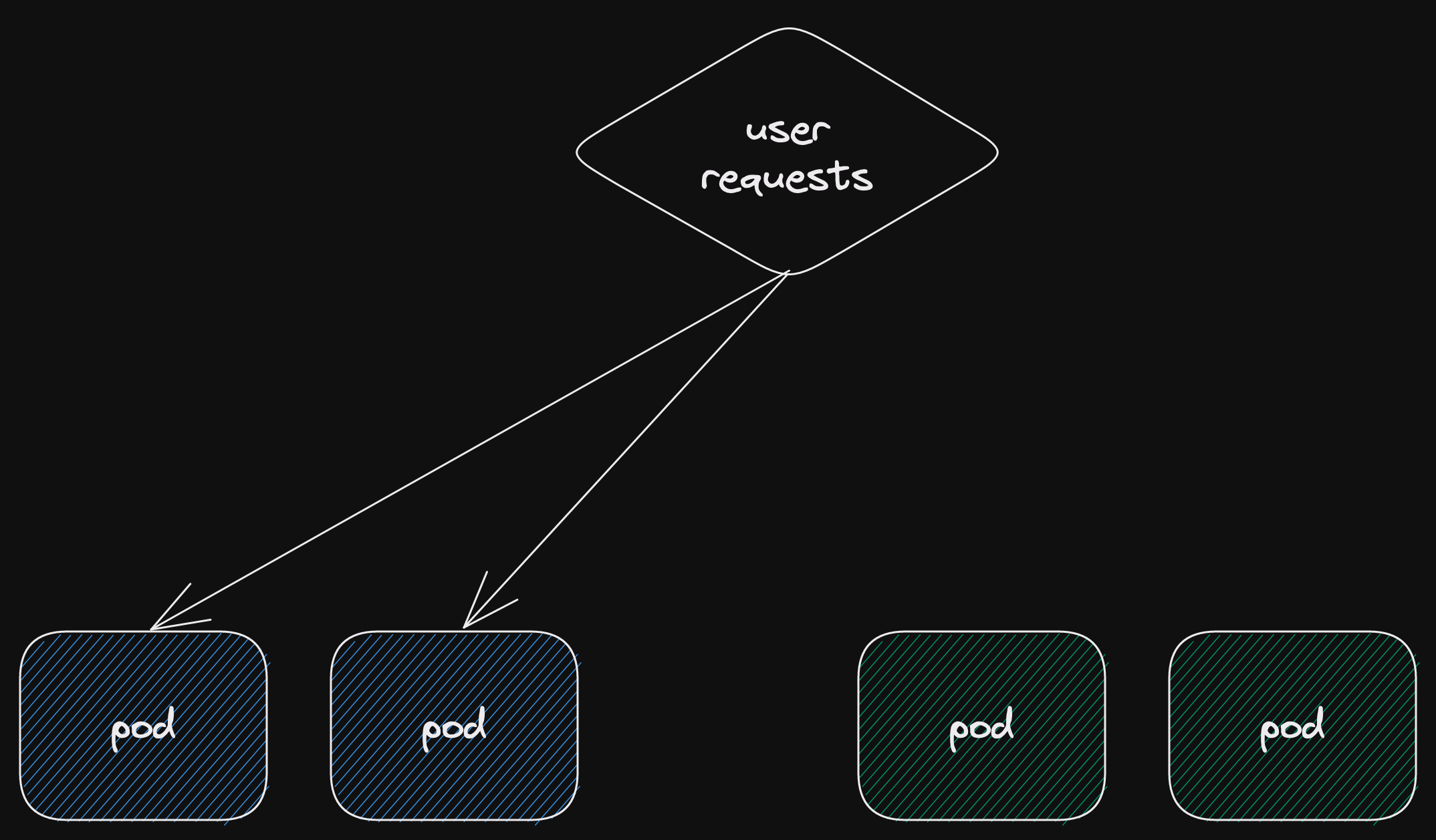
Once you're happy that the new (green) deployment is healthy, switch user requests.
Now the green deployment is receiving all the user requests.
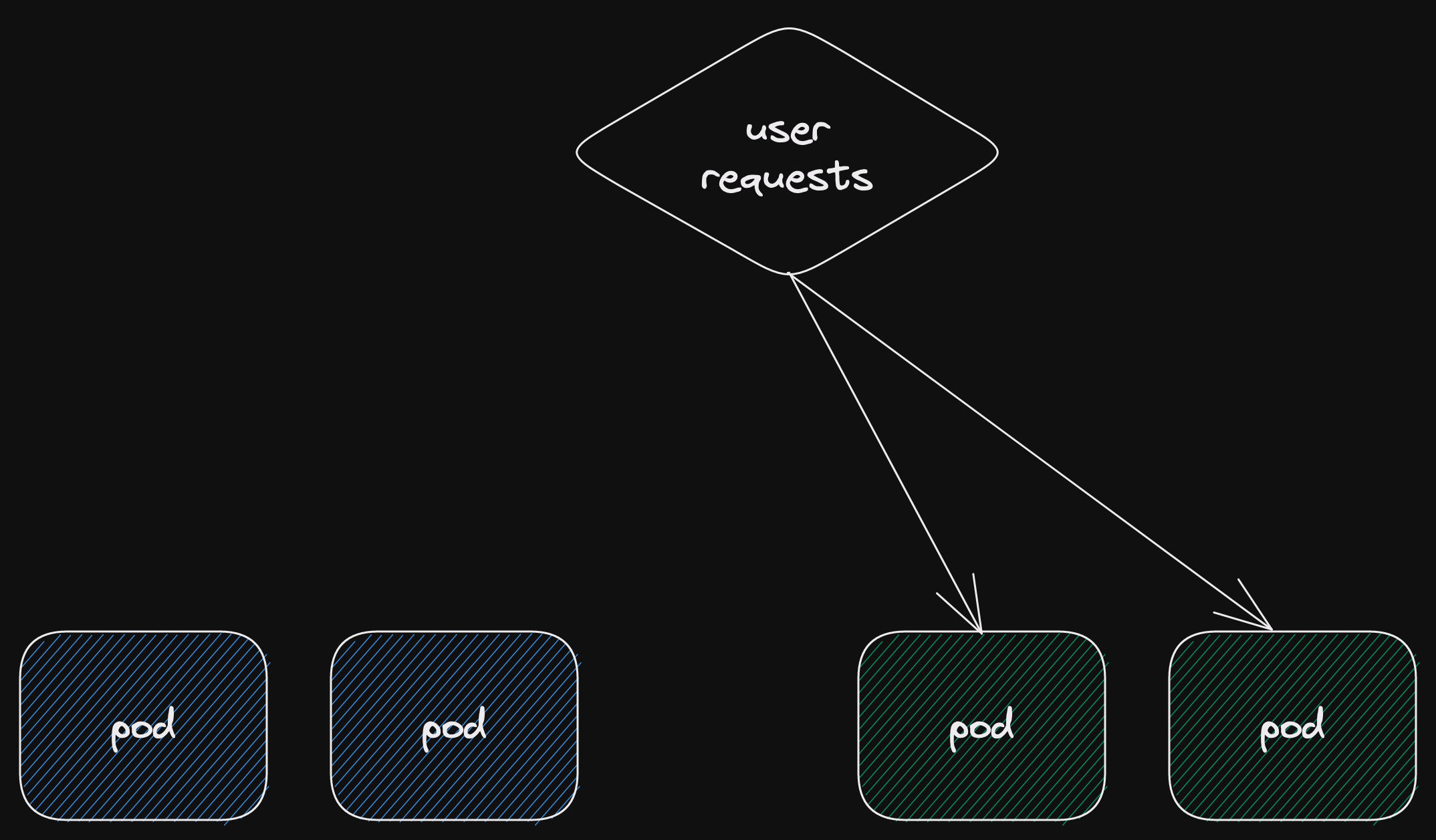
Let's assume everything is going fine.
The green deployment is handling user requests.
Now we can remove our blue deployment.
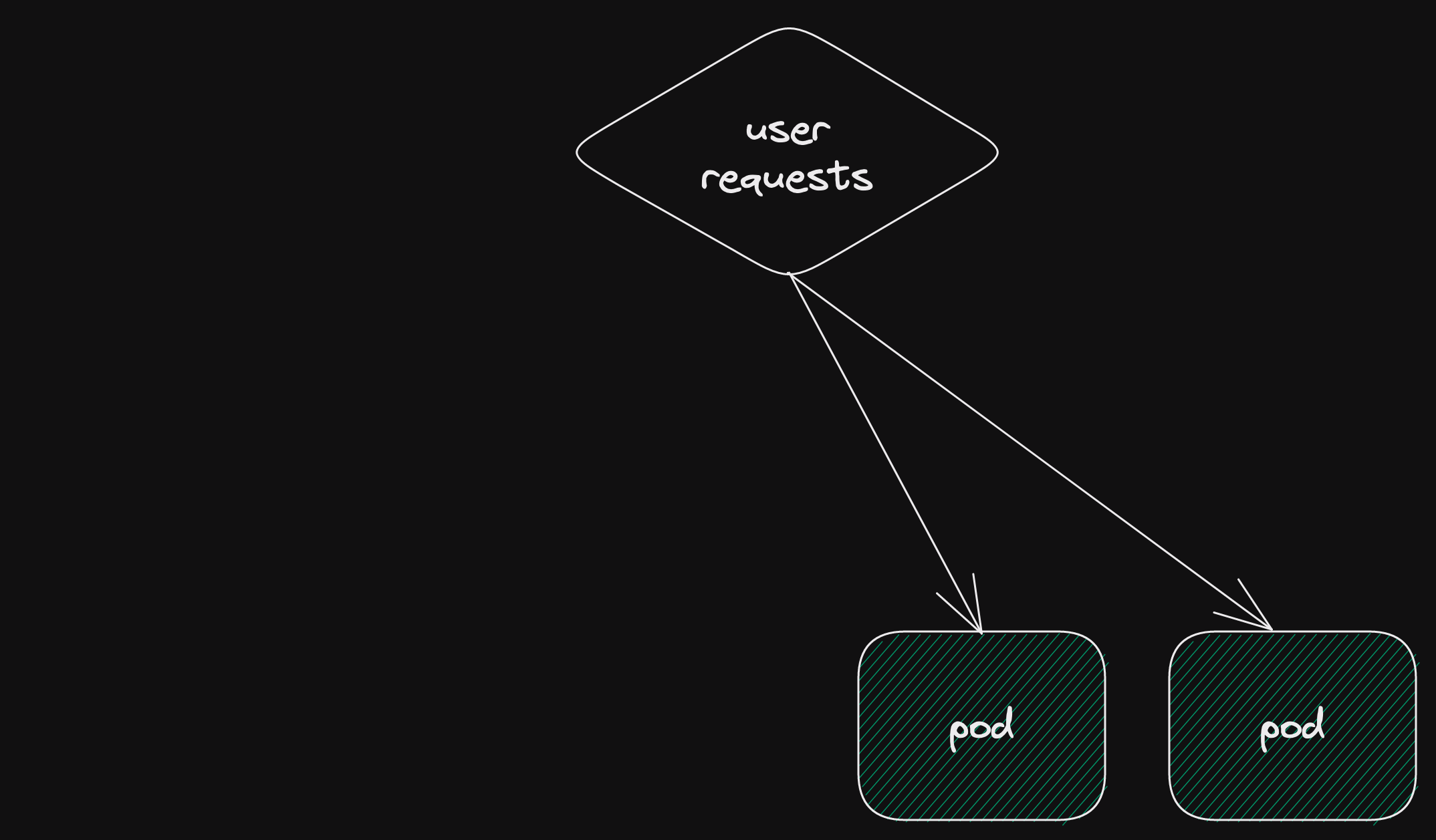
However, if there is a problem, we can quickly route our user requests back to the blue deployment.
The next image is just step 2 again.
It's that easy.
Now we can safely work our what's wrong with our new (green) deployment before trying again.
the answer
A pod has to be able to attach to a persistent volume.
We use WaitForFirstConsumer volume claims, so the volume isn't created until after the pod has a node.
And the pod will be allocated so that it conforms to the topology spread constraints.
But during deployment, we have more than just the 2 pods present.
Here's what happened.
We have our current deployment (blue).
Two pods, happily obeying the topology spread constraints.
We have 3 availability zones.
This means that we must have 2 zones with a single pod each, and 1 zone without any.
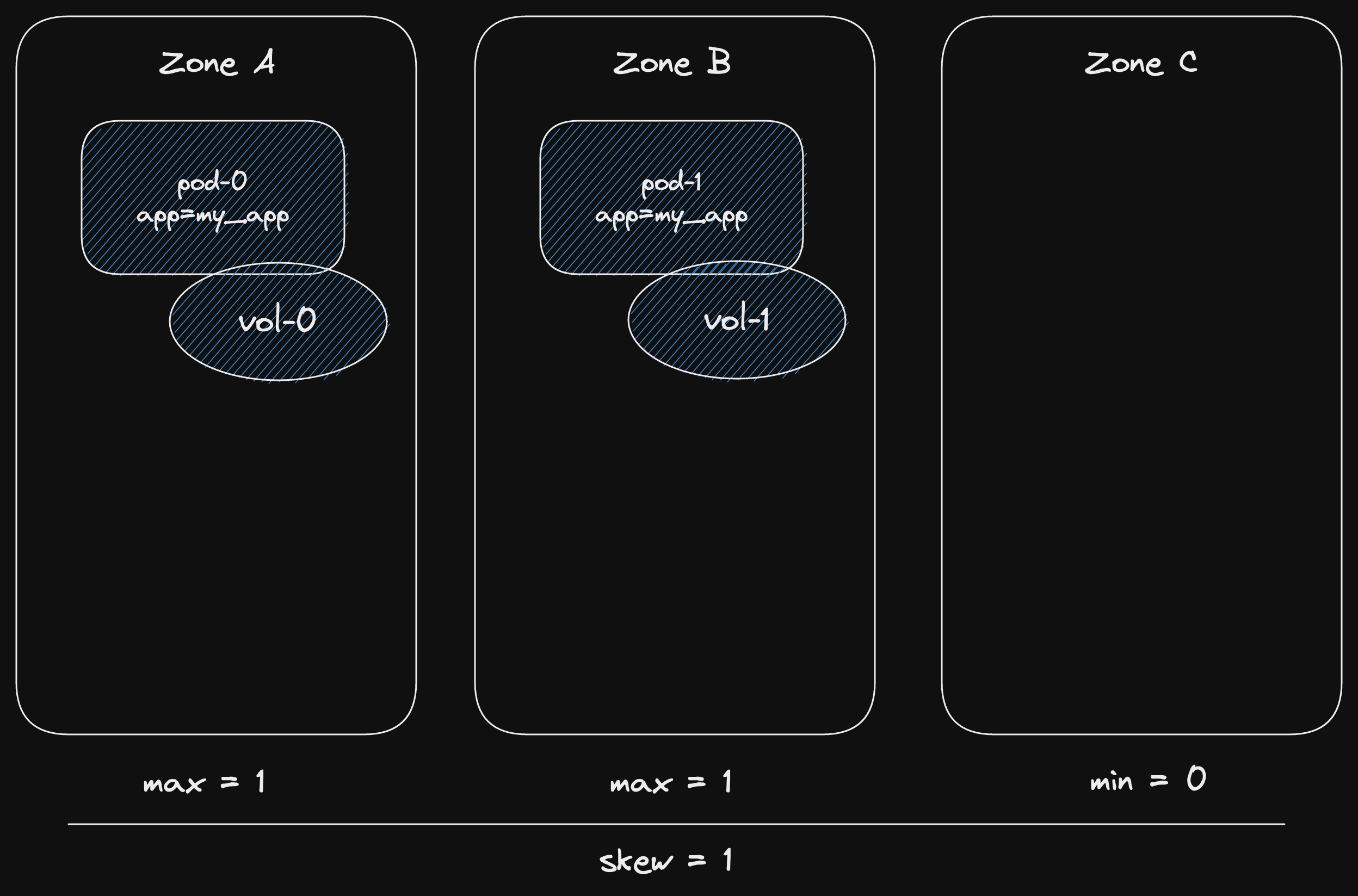
Now we add two pods from our new deployment (green).
All pods have the label app=my_app.
So the topology constraints apply to the pods from both deployments together.
This means that we must have 2 zones with a single pod each, and 1 zone with 2 pods.
Which is perfectly legal under our topology spread constraints.
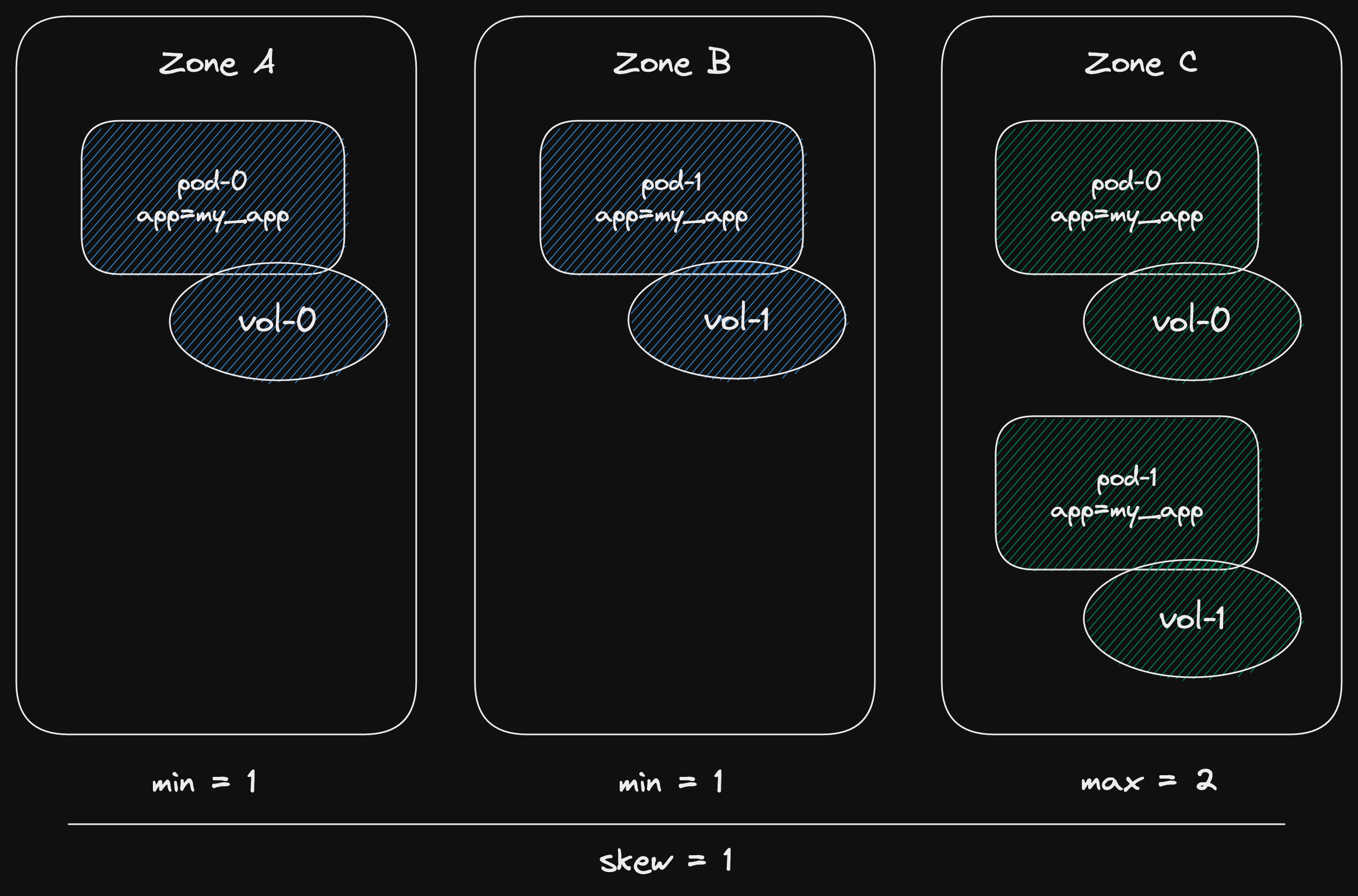
Then we finish our deployment.
The new deployment (green) becomes the current one.
The previously current deployment is removed.
Leaving us with two pods in a single zone.
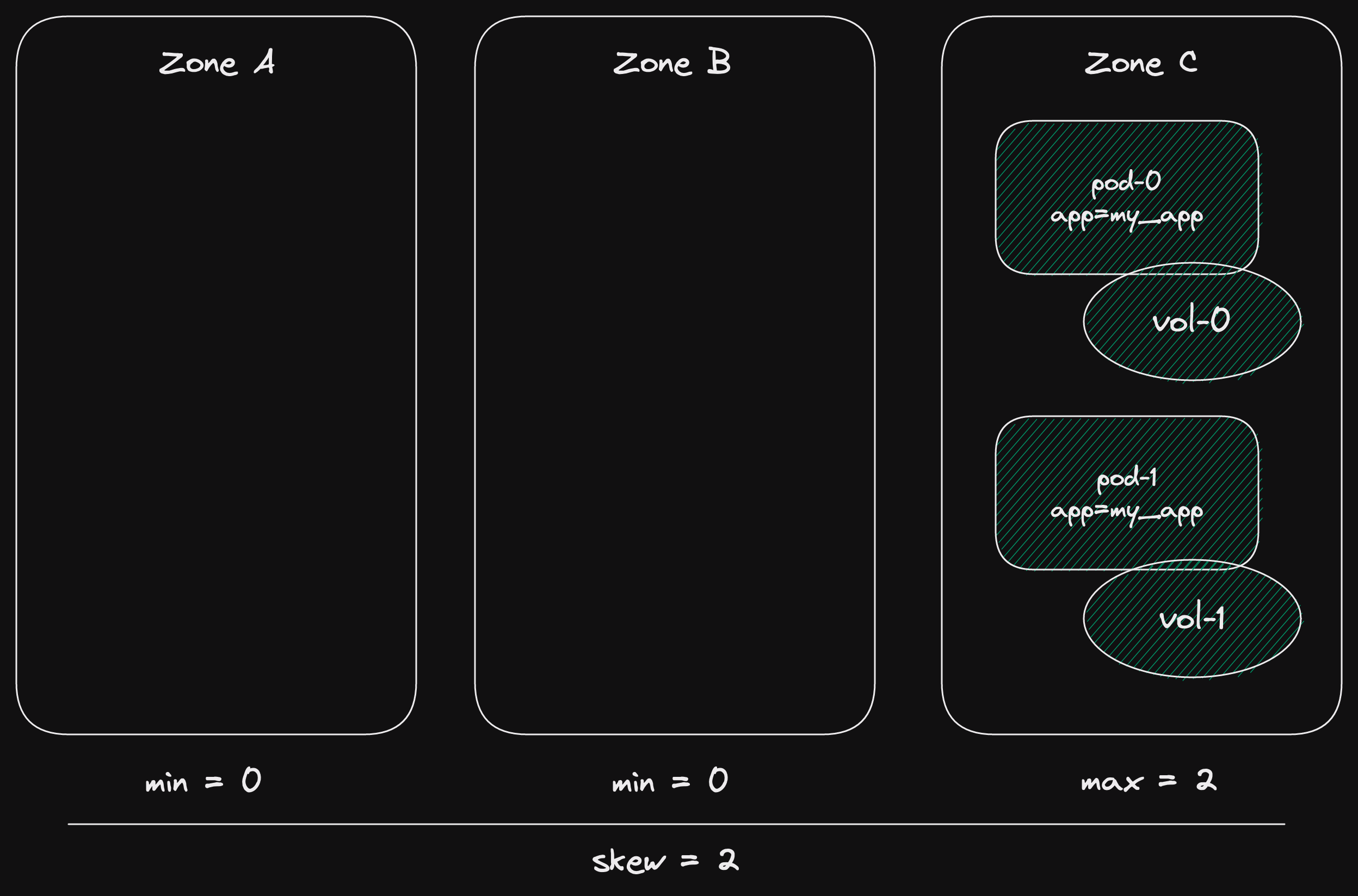
This is all fine, until a pod gets evicted.
Our staging cluster runs on spot instances.
So pods get evicted a lot.
This is great to find latent availability problems with your deployments.
Which is how we got here in the first place.
If a pod gets evicted, the volume stays in the same zone.
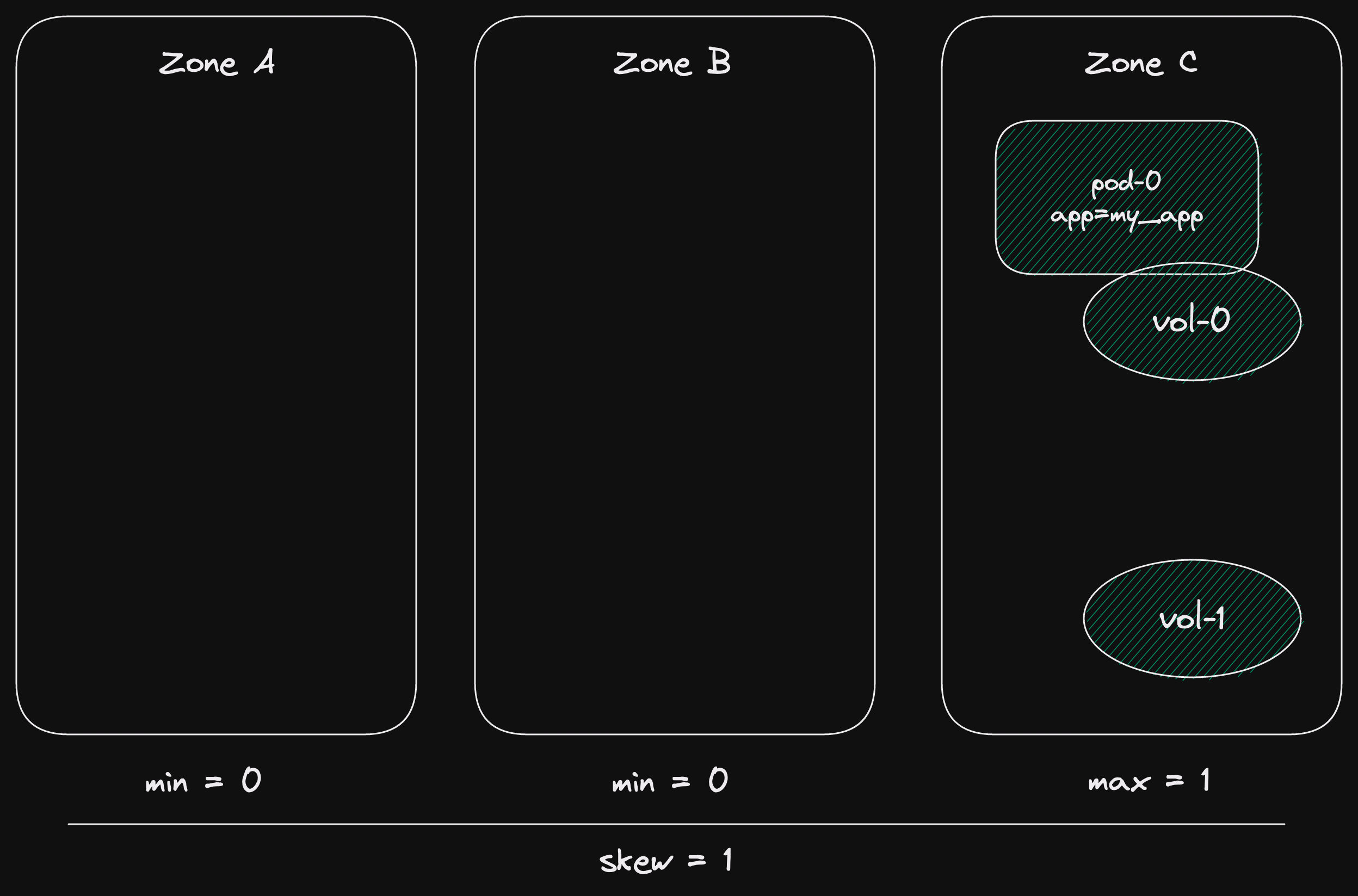
Now kubernetes tries to schedule the pod.
It has to go in the zone with the volume it needs to attach to.
That's what this part of the NotTriggerScaleUp message means:
4 node(s) had volume node affinity conflict
But it can't, because we already have the only pod in that zone.
So our current skew is 1 - 0 = 1.
If we put another pod in that zone, our skew will become 2 - 0 = 2.
And a skew of 2 isn't allowed!
the fix
The fix is relatively simple.
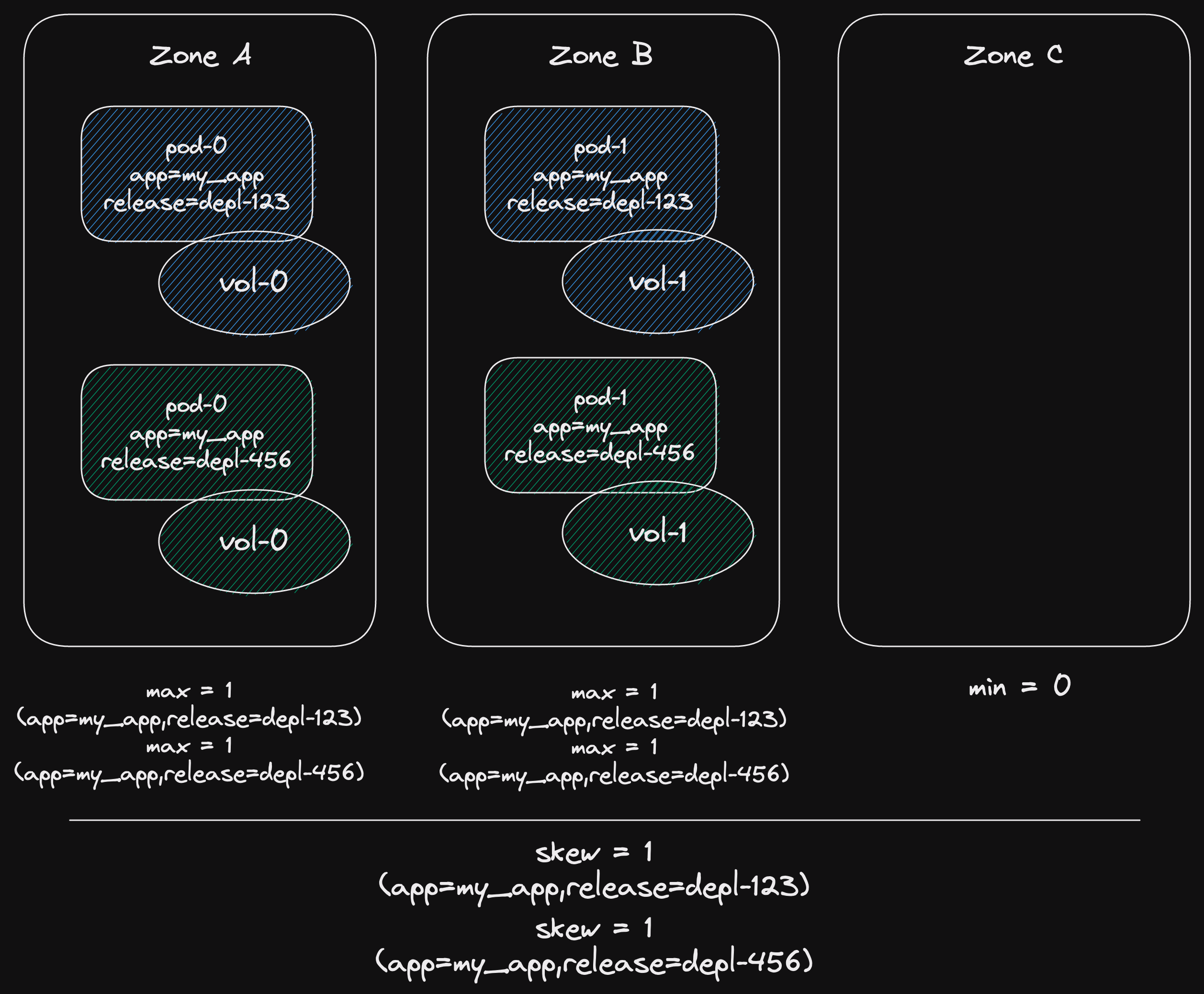
Each pod already has a label with the deployment identifier in it, release=depl-123.
So we include this in our topology spread constraints.
Then it will apply to all pods that match both labels app=my_app,release=depl-123.
And the topology spread constraints will only apply to pods across a single deployment.
The point at which both blue and green deployments are active could occupying only zones A and B.
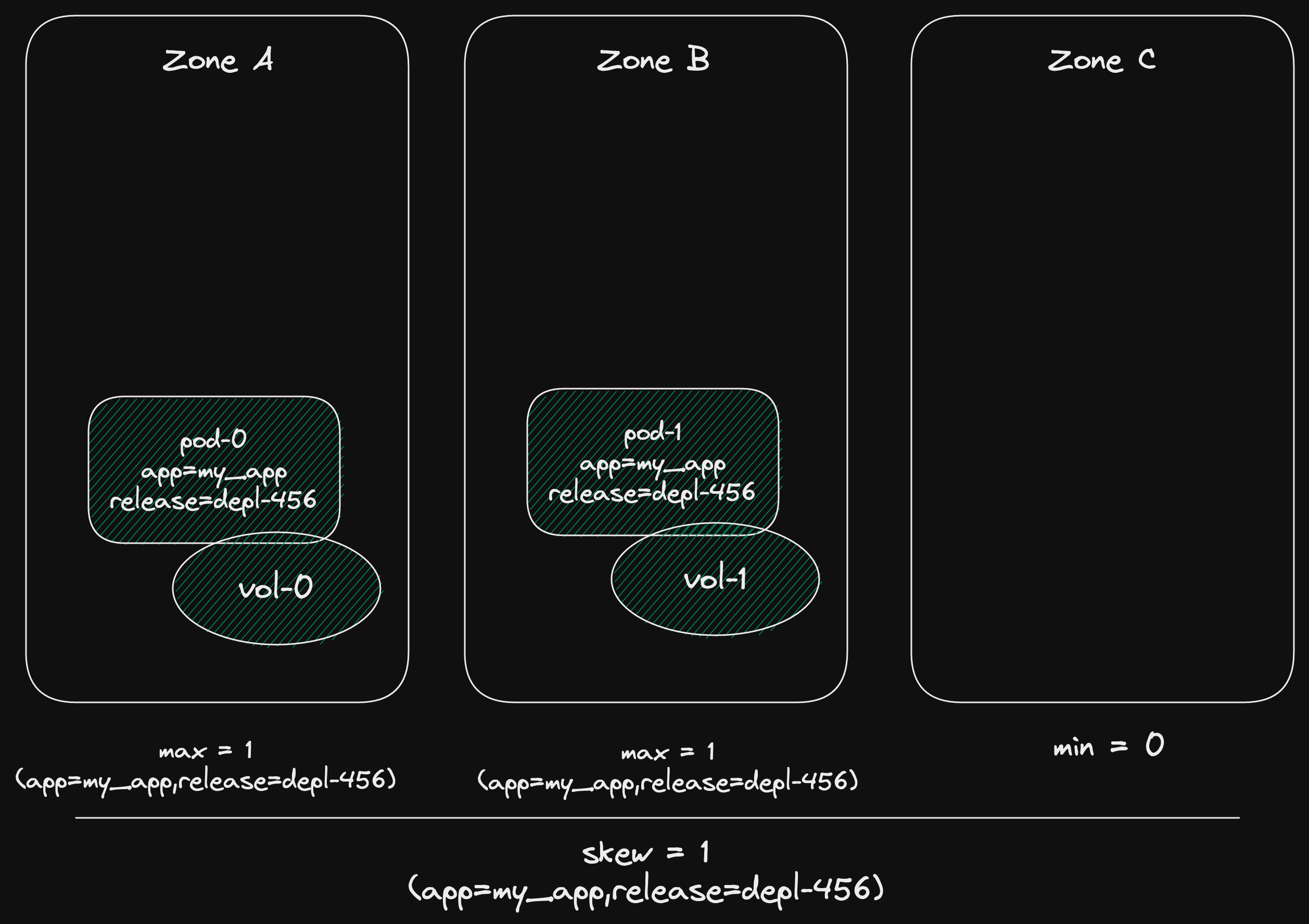
Now we remove the blue deployment.
And the green deployment still adheres to the topology spread constraints.
We've solved another hairy problem.
Improving the sleep cycle of our on-call engineer.