how big is your future?
by on Thursday, 31 October 2024
I am, of course, talking about std::future::Future.
There are two ways of creating a Future in Rust, you can define some struct or enum, and then implement the Future trait on it or via Rust's async keyword. Any async block (async { .. }) or async function (async fn foo() { .. }) returns a future. If you want to learn more about how this works, have a look at my series of posts on how I finally understood async/await in Rust.
In the case of the async block or function, the type is opaque. You, as the developer, don't know anything about it except that it implements Future and so you can pass it into a function that accepts impl Future as a parameter. But the compiler knows much more about it (the compiler built it after all). One critical piece of information that the compiler knows about every future is its size. How many bytes it takes up on the stack.
The compiler must know this about anything that can be passed as an impl Trait parameter, because that will be placed on the stack.
And the size of a future is exactly what we're talking about today.
how big is that future?
There's no secret to getting the size of any type in Rust, as long as the compiler knows it at compile time, you can too. Via the std::mem::size_of function. To get the size of some struct Foo you use it like this:
std::mem::size_of::<Foo>()
If you want to get the size of some type that you can't name, then you can use a generic function. Since this post is all about the size of futures, let's write a function that will return exactly that.
fn how_big_is_that_future<F: Future>(_fut: F) -> usize {
std::mem::size_of::<F>()
}
This generic function will be monomorphised during compilation. That's a fancy way of saying that the Rust compiler will make a copy of this function for every different F that it is called with (which could be a lot, but it's a bounded number). Because of that, the compiler knows the size at compile time!
why do we care?
You might be asking yourself, why do we care how big futures are? The reason is that they're often passed on the stack (e.g. every Tokio method to spawn a task takes a future on the stack), and you have a limited amount of stack space, by default each thread that the standard library spawns gets 2 MiB of stack.
Of course, lots of things can be big and get passed on the stack. So why is it that we're specifically interested in futures?
There are 2 reasons for this:
- Futures are often auto-generated by the compiler (
asyncfunctions and blocks). - Futures generated from
asyncfunctions and blocks may capture more than you expect.
Futures are state machines, and anything held across an await point needs to be stored until the future is next polled. I've been told that the Rust compiler isn't very good at determining what needs to be held across an await point. It seems that there are a number of issues with code generation for Coroutines which make them bigger than they need to be, and futures created from async functions and blocks are a subset of this. See the metabug rust-lang/rust#69826 for details.
It's easy enough to build contrived examples of very large futures. Here's one that I prepared earlier:
async fn nothing() {}
async fn huge() {
let mut a = [0_u8; 20_000];
nothing().await;
for (idx, item) in a.iter_mut().enumerate() {
*item = (idx % 256) as u8;
}
}
We create a very large array, 20 thousand u8 elements, we await a future that does nothing, and then populate the array with some values.
Since we don't actually read the elements out of the array, only write to them, we might reasonably expect that the whole array gets optimised out, but that isn't the case. Even in release mode, this future weighs in at 20_002 bytes. So we have 20_000 bytes for our array, and another 2 bytes in there for that nothing future.
(I'm going to write large numbers using an underscore _ thousands separator. This is a valid Rust integer literal, and we can avoid the whole point . vs. comma , thousands separator debate.)
Of course, this example is quite obvious. But remember that each future that is awaited needs to be stored (while it's being awaited) too. And you don't always know how big those futures are. Like this async function:
async fn innocent() {
huge().await;
}
This future comes in at 20_003 bytes. The size of the inner future and 1 more byte, which is actually pretty efficient!
Now we know that we can find out how big futures are, we know that they can be very big indeed, so what can we do?
box it up
If a future is very large, you may want to wrap it in a std::boxed::Box, which will place it on the heap where there is much more space than on the stack.
If you want to spawn a task with a large future, you could box it first. To box a future, you need to use Box::pin instead of Box::new because futures need to be pinned to be polled. Let's instead box the huge async function before awaiting it.
async fn not_so_innocent() {
Box::pin(huge()).await;
}
This function will now weigh in at 16 bytes (on my 64-bit machine). Of course those 20_002 bytes of the huge async function future are still there, but they're safely on the heap now, where they're not going to cause a stack overflow.
auto-boxing in tokio
Futures can be especially large when compiling in debug mode where the compiler keeps some extra information around and may not optimise as much out either.
Going all the way back to tokio-rs/tokio#4009 in 2021, Tokio started checking the size of user provided futures when compiling in debug mode and boxing them if they were over a certain size. That PR references the issue Excessive stack usage when using tokio::spawn in debug builds (tokio-rs/tokio#2055) from the beginning of 2020. Any future over 2 KiB will get put in a Box as soon as it gets passed to tokio::spawn (or similar).
In the latest Tokio release (1.41.0), this auto-boxing behaviour was extended to release mode builds as well, but with a limit of 16 KiB for release and keeping the 2 KiB limit for debug builds (tokio-rs/tokio#6826).
So if we spawn that huge future, it will very quickly get moved to the heap and not cause a stack overflow.
tokio::spawn(huge());
task size in tracing instrumentation
Another thing that made it into the Tokio 1.41.0 release is an addition to the tracing instrumentation to include the size of the future which is used to spawn each task. That this landed at the same time as the release mode auto-boxing is a complete coincidence.
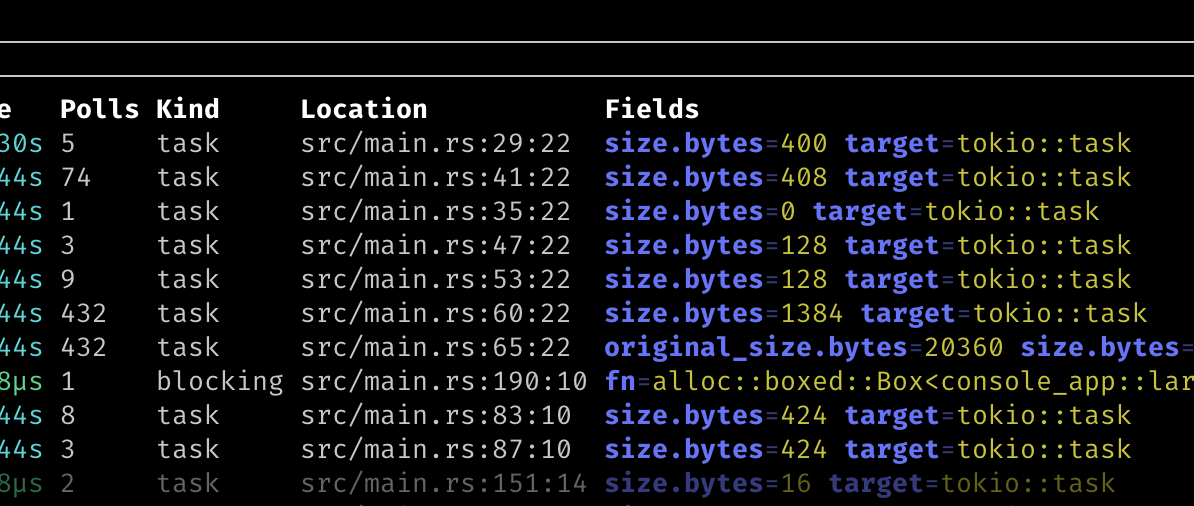
However, because the auto-boxing occurs in release mode as well now, the tracing instrumentation provides 2 new fields for each runtime::spawn span:
size.byte- the size of the future spawned into this taskoriginal_size.bytes- the original size of the future, in the case that it has been auto-boxed (optional)
And because Tokio Console will display any extra fields it finds, you would already see that in in the task view (list and details):
In addition, there are now 2 new lints which will warn you about tasks based on the size of the future that is driving them.
The first one will warn if a task's future has been auto-boxed, the second will warn if the task's future is larger than 1 KiB. The two lints won't ever trigger at the same time, because Tokio's auto-boxing feature will mean that the final size of a future is always the size of a box (16 bytes 64-bit machines).
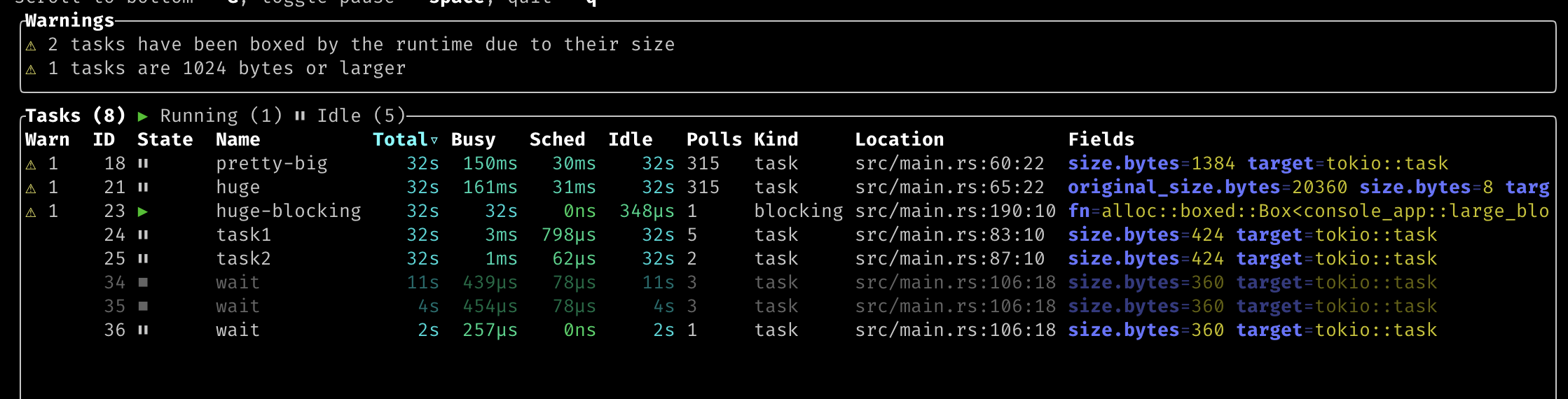
Here we see the 2 lints being triggered by different tasks in a test app.
If we go into the task details screen, the the warning for a given task is more specific and gives the before and after size:
⚠ This task's future was auto-boxed by the runtime when spawning, due to its size (originally 20360 bytes, boxed size 8 bytes)
The same is true for a task with a future that is large, but hasn't been auto-boxed:
⚠ This task occupies a large amount of stack space (1384 bytes)
This last lint may be the least useful, as futures can become quite large without it necessarily becoming a problem, but it's probably still good to know.
It's great that we can check this at runtime, but if the compiler knows how big the future is (because of monomorphisation), wouldn't it be cool if we could lint for this at compile time? This is Rust after all...
future size lints in clippy
This is Rust after all. And there is already a Clippy lint called large_futures which will alert you to very large futures! It was added in Rust 1.70 (which is over a year old at the time of writing).
The large_futures lint is in the Pedantic group, so it is set to allow by default (and so you won't see it). The future size threshold defaults to 16 KiB, but can be configured.
So now you know how to check at least your own futures for being too large at compile time!